
728x90
2022.03.07 - [데이터 분석/02. Data Processing] - [전처리] Data Reduction(데이터 축소) - 차원축소
[전처리] Data Reduction(데이터 축소) - 차원축소
2022.03.06 - [데이터 분석/02. Data Processing] - [전처리] Data Transformation(데이터 변환) [전처리] Data Transformation(데이터 변환) - 정규화 2022.03.04 - [데이터 분석/02. Data Processing] - [전처리..
xod22.tistory.com
Data Reduction(데이터 축소)의 두번째 방법인 수치적 축소에 대해 적어보려고 합니다!

Numerosity reduction(수치적 축소)
: 데이터 크기를 줄이는 방법
~랜덤샘플링~
1. 패키지 임포트
from sklearn.datasets import load_iris
import pandas as pd
iris=load_iris()
2. 데이터 확인
#x컬럼만 data에 저장
data=pd.DataFrame(iris.data, columns=['Sepal length', 'Sepal width', 'Petal length', 'Petal width'])
print(data.info())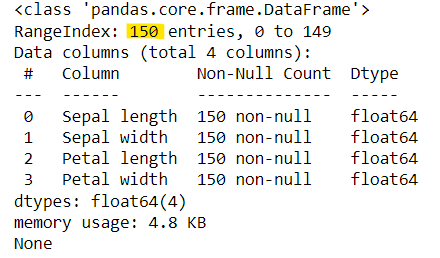
데이터의 개수가 150개 인 것을 확인
3. 샘플링
: 샘플링할 때 재현할 수 있도록 random_state=1000으로 설정!
~첫번째 방법 : 개수로 샘플링~

samn=data.sample(n=15, random_state=1000) #15개 샘플링
~두번째 방법 : 비율로 샘플링~
samf=data.sample(frac=0.1, random_state=1000) #전체의 10% 샘플링(15개임)
=> 결과 확인
#같은 결과가 나옴
print(samn.head(5))
print(samf.head(5))
~세번째 방법 : 중복 허락하고 샘플링~

#replace=True : 뽑힌걸 또 뽑아도됨
samwr=data.sample(n=15, replace=True, random_state=1000)
=>결과 확인
print(samwr.head(15))
이렇게 이미 한차례 샘플링 된 결과 값이 또 샘플링될 수 있다..!
728x90
'🔍 데이터 분석 > 02. Data Processing' 카테고리의 다른 글
| [태블로 신병 훈련소 20기] DAY10 Tableau Prep을 활용한 데이터 전처리 (0) | 2023.09.08 |
|---|---|
| [전처리] 네이버 영화 평점 크롤링 데이터 - Preprocessing (0) | 2022.03.24 |
| [전처리] Data Reduction(데이터 축소) - 차원축소 (0) | 2022.03.07 |
| [전처리] Data Transformation(데이터 변환) - 새로운 속성 만들기 (0) | 2022.03.06 |
| [전처리] Data Transformation(데이터 변환) - 정규화 (0) | 2022.03.06 |